AI ยังใช้คอมพิวเตอร์ไม่เก่งอย่างที่คิด — แต่กำลังดีขึ้นเร็วมาก
ถ้าคุณเคยดู Demo ของ AI ที่เปิดเบราว์เซอร์ กรอกฟอร์ม ย้ายไฟล์ หรือแก้ไขเอกสารได้ด้วยตัวเอง คุณอาจคิดว่า AI ใกล้จะทำงานบนคอมพิวเตอร์ได้เหมือนมนุษย์แล้ว
แต่จะรู้ได้อย่างไรว่า AI "เก่งจริง" หรือแค่ "ดูเก่ง" ใน Demo ที่จัดฉากมา?
คำตอบอยู่ที่ Benchmark — และ Benchmark ที่น่าเชื่อถือที่สุดสำหรับการทดสอบ AI บนคอมพิวเตอร์จริงคือ OSWorld ซึ่งได้รับการตีพิมพ์ในงาน NeurIPS 2024 และกลายเป็นมาตรฐานที่ทั้งอุตสาหกรรม AI ใช้วัดผลกันอยู่ในปัจจุบัน
OSWorld คืออะไร?
OSWorld (Open-ended tasks in real computer environments) เป็น Benchmark ที่ออกแบบมาเพื่อทดสอบ AI Agent บน คอมพิวเตอร์จริง — ไม่ใช่สภาพแวดล้อมจำลอง ไม่ใช่แค่ตอบคำถาม Choice หรือเขียนโค้ดในกล่องทดสอบ แต่ต้อง ลงมือทำงานจริง บนหน้าจอคอมพิวเตอร์เหมือนที่มนุษย์ทำ
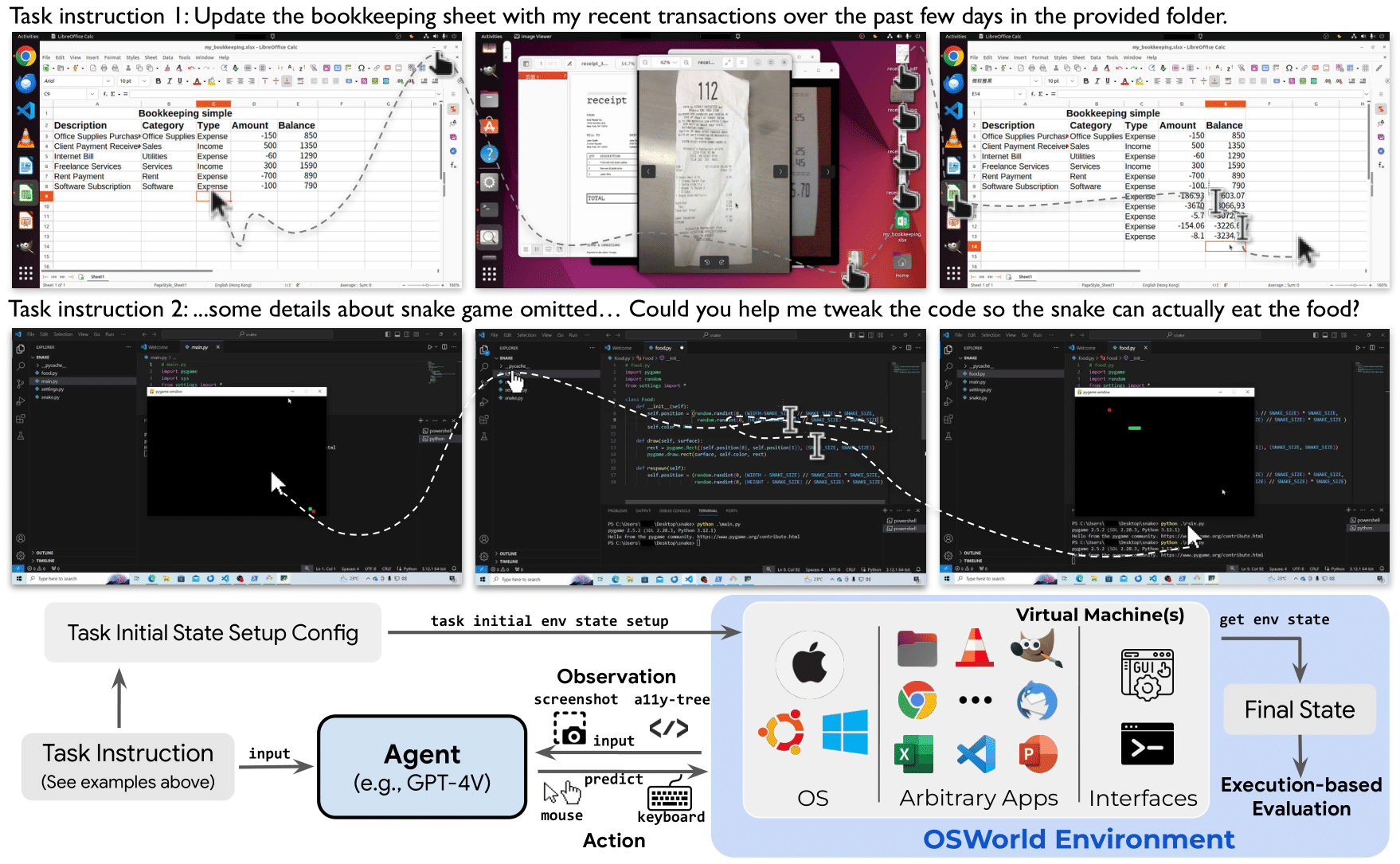
ทำไมถึงต่างจาก Benchmark อื่น?
Benchmark ส่วนใหญ่ทดสอบ AI แบบ "ถาม-ตอบ" — ให้โจทย์แล้วดูว่า AI ตอบถูกหรือไม่ แต่ OSWorld ทดสอบแบบ "ลงมือทำ" — ให้เป้าหมาย แล้ว AI ต้อง:
- มองเห็นหน้าจอ (Screenshot หรือ Accessibility Tree)
- คิดว่าต้องทำอะไร เพื่อบรรลุเป้าหมาย
- ควบคุมเมาส์และคีย์บอร์ด เพื่อดำเนินการ
- ตรวจสอบผลลัพธ์ ว่าสำเร็จหรือไม่ แล้วปรับแผนถ้าจำเป็น
ทั้งหมดนี้เกิดขึ้นบนระบบปฏิบัติการจริง — Ubuntu, Windows และ macOS
Benchmark ที่ครอบคลุมแค่ไหน?
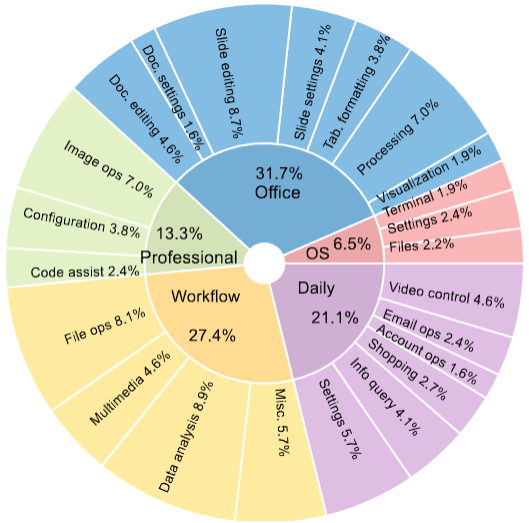
OSWorld ประกอบด้วย 369 งาน ที่ครอบคลุม 4 ประเภทหลัก:
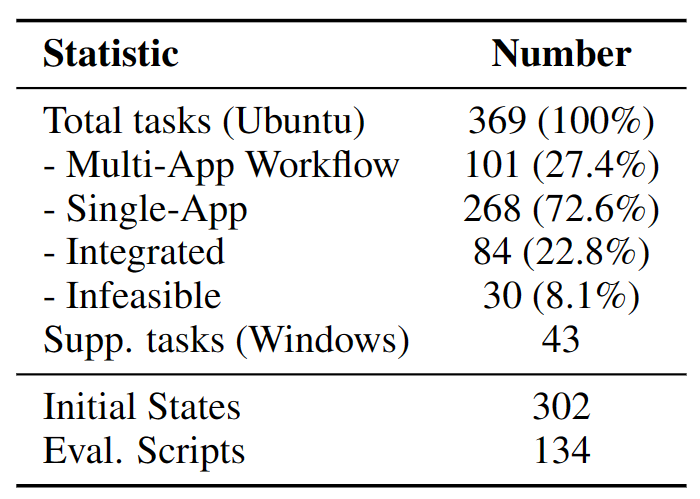
- Web Application — ค้นหาข้อมูล กรอกฟอร์ม จัดการอีเมล
- Desktop Application — แก้ไขเอกสาร สร้าง Spreadsheet ปรับแต่งรูปภาพ
- OS File I/O — จัดการไฟล์ ย้ายโฟลเดอร์ เปลี่ยนการตั้งค่าระบบ
- Cross-Application Workflow — งานที่ต้องใช้หลายแอปร่วมกัน เช่น ดึงข้อมูลจากเว็บมาใส่ใน Spreadsheet แล้วสร้างกราฟ
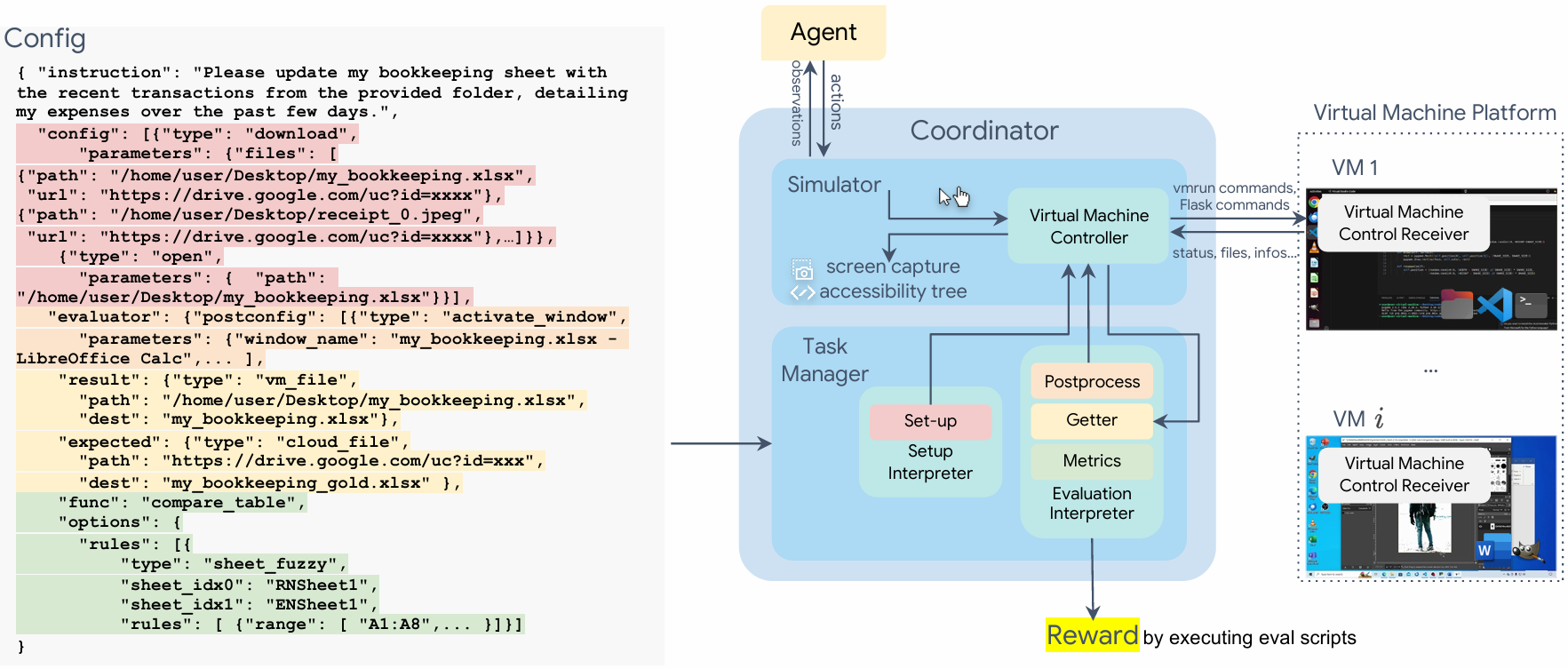
แต่ละงานมี สคริปต์ตั้งค่าเริ่มต้น (ทำให้ทุกการทดสอบเริ่มจากจุดเดียวกัน) และ สคริปต์ประเมินผลแบบ Execution-based (ไม่ได้แค่ดูว่าคลิกถูกตำแหน่ง แต่ตรวจสอบว่าผลลัพธ์สุดท้ายถูกต้องจริงหรือไม่)
ผลลัพธ์ที่น่าตกใจ — และพัฒนาการที่น่าจับตา
จุดเริ่มต้น (2024): AI ทำได้แค่ 12%
เมื่อ OSWorld เปิดตัวในปี 2024 ผลลัพธ์ทำให้ทั้งวงการตื่นตัว — AI ที่ดีที่สุดทำสำเร็จเพียง 12.24% ของงานทั้งหมด ขณะที่มนุษย์ทำได้ 72.36%
ช่องว่าง 60 จุดนี้บอกให้รู้ว่า แม้ AI จะเก่งเรื่องตอบคำถามและเขียนโค้ด แต่การ "ใช้คอมพิวเตอร์" จริงๆ ยังห่างไกลจากมนุษย์มาก
ปัจจุบัน (2026): ช่องว่างกำลังปิดลง
สองปีผ่านไป ภาพเปลี่ยนไปอย่างมาก บน OSWorld-Verified (เวอร์ชันปรับปรุงที่แก้ไขปัญหาและเพิ่มความน่าเชื่อถือ):
| อันดับ |
ระบบ |
คะแนน |
| 1 |
CoACT-1 |
60.76% |
| 2 |
Agent S2.5 (w/ o3) |
56.0% |
| 3 |
UiPath Screen Agent (Claude Opus 4.5) |
53.6% |
| 4 |
GTA1 (w/ o3) |
53.1% |
| 5 |
Claude Sonnet 4.5 |
43.9% |
| 6 |
UI-TARS |
40.0% |
| — |
มนุษย์ |
~72% |
จาก 12% เป็น 60% ในเวลาสองปี — พัฒนาขึ้นเกือบ 5 เท่า
สิ่งที่ OSWorld เปิดเผยเกี่ยวกับจุดอ่อนของ AI
การวิเคราะห์ผลลัพธ์อย่างละเอียดเผยให้เห็นจุดอ่อนสำคัญหลายประการ:
GUI Grounding ยังเป็นปัญหา
AI ยังมีปัญหาในการ "เข้าใจ" สิ่งที่เห็นบนหน้าจอ — ปุ่มไหนคือปุ่มไหน เมนูอยู่ตรงไหน ต้องคลิกที่จุดไหนบนหน้าจอ โดยเฉพาะเมื่อ UI มีความซับซ้อนสูง
ความรู้เชิงปฏิบัติยังขาด
AI อาจ "รู้" ว่า LibreOffice Calc ทำอะไรได้ แต่ไม่รู้ว่า ต้องกดปุ่มอะไร ตรงไหน ในลำดับใด เพื่อทำสิ่งนั้น ความรู้ทางทฤษฎีกับทักษะปฏิบัติยังห่างกัน
ไม่ทนต่อการเปลี่ยนแปลง UI
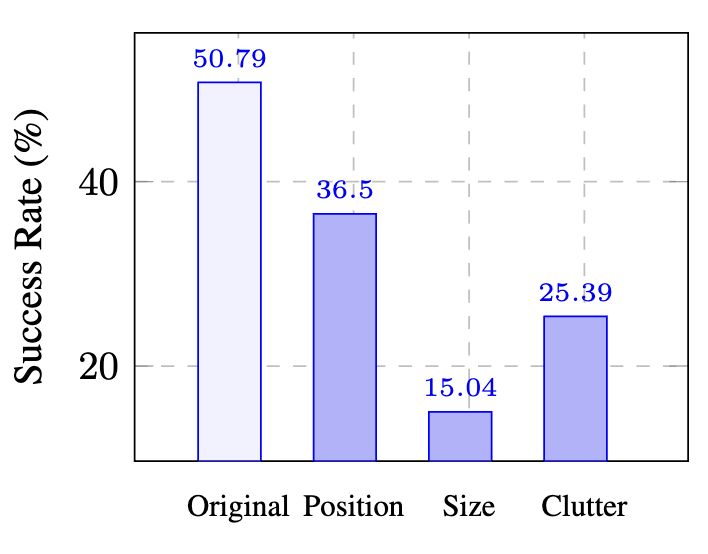
เมื่อ Layout ของหน้าจอเปลี่ยนไปเล็กน้อย (เช่น ปุ่มย้ายตำแหน่ง หน้าต่างเปลี่ยนขนาด) ประสิทธิภาพของ AI ลดลงอย่างมีนัยสำคัญ ขณะที่มนุษย์ปรับตัวได้โดยแทบไม่รู้สึก
Resolution มีผล
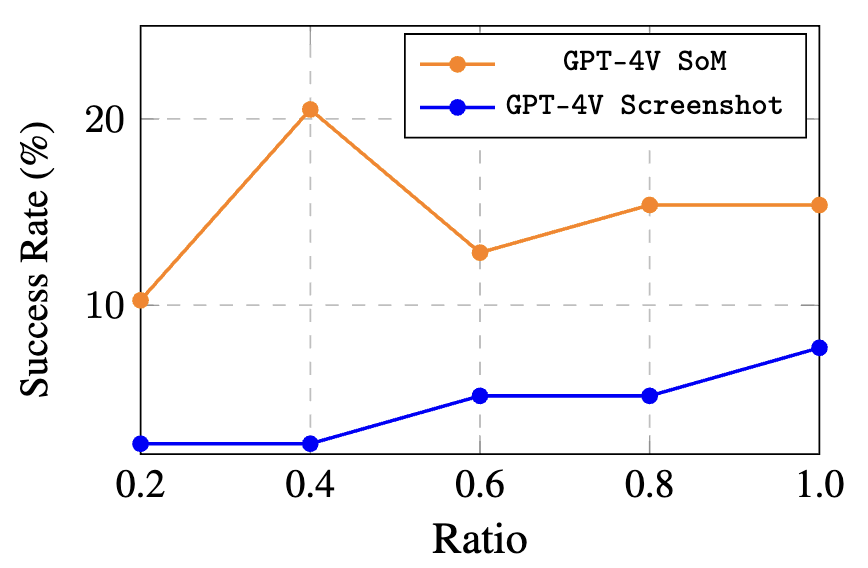
ยิ่งความละเอียดของ Screenshot สูงขึ้น AI ยิ่งทำงานได้ดีขึ้น ซึ่งบ่งบอกว่า AI ยังต้องพึ่งพา "การมองเห็น" อย่างมาก และการบีบอัดภาพที่ส่งไปให้ AI มีผลกระทบโดยตรง
Agentic Framework เหนือกว่า Foundation Model เปล่าๆ
สิ่งที่น่าสนใจที่สุดจาก Leaderboard ล่าสุดคือ — ระบบที่อยู่อันดับต้นๆ ไม่ใช่ AI Model ตัวเดี่ยว แต่เป็น Framework ที่ประสานหลายส่วนเข้าด้วยกัน
CoACT-1 ที่ได้อันดับ 1 ใช้ Reasoning Model ร่วมกับ Agentic Framework ที่วางแผน ลงมือทำ และตรวจสอบผลลัพธ์เป็นวงจร ส่วน Agent S2.5 ใช้ Experience-augmented Hierarchical Planning — เรียนรู้จากประสบการณ์การทำงานที่ผ่านมาเพื่อวางแผนการทำงานครั้งถัดไป
สิ่งนี้ยืนยันว่า การ "ใช้คอมพิวเตอร์" ไม่ใช่แค่เรื่องของ AI Model ที่ฉลาดขึ้น แต่ต้องการ "ระบบ" ที่ครบวงจร — วางแผน ลงมือทำ เรียนรู้ ปรับตัว
นัยสำคัญสำหรับองค์กร
Automation กำลังจะเปลี่ยนระดับ
เมื่อ AI สามารถ "ใช้คอมพิวเตอร์" ได้ดีขึ้น งานที่เคยต้องใช้คนนั่งหน้าจอจะเริ่มถูกทำโดย AI Agent มากขึ้น ไม่ใช่แค่งานที่มี API ให้เชื่อมต่อ แต่รวมถึงงานที่ต้อง คลิก พิมพ์ ลากวาง บนแอปพลิเคชันที่ไม่ได้ออกแบบมาให้ AI ใช้
UiPath ที่ได้อันดับ 3 คือตัวอย่างที่ชัดเจน — บริษัท RPA ยักษ์ใหญ่ที่เคยพึ่งพา Rule-based Automation กำลังเปลี่ยนผ่านมาใช้ AI เป็นแกนหลัก
เลือก AI ด้วยข้อมูล ไม่ใช่การตลาด
OSWorld ให้เครื่องมือที่องค์กรสามารถใช้ เปรียบเทียบ AI Model อย่างเป็นกลาง แทนที่จะเชื่อ Demo จากผู้ขาย ลองดูคะแนน OSWorld ของ Model ที่กำลังพิจารณา — มันจะบอกคุณได้ชัดเจนกว่าว่า AI ตัวนั้นทำงาน "บนคอมพิวเตอร์จริง" ได้แค่ไหน
ยังมี Headroom อีกมาก
แม้จะพัฒนาขึ้นมาก แต่ช่องว่างระหว่าง 60% กับ 72% ของมนุษย์ยังมีอยู่ และ 72% ของมนุษย์ก็ไม่ใช่ 100% — หลายงานที่ยากแม้แต่คนยังทำไม่สำเร็จ สิ่งนี้บอกว่า AI ยังไม่พร้อมทำงานทดแทนมนุษย์ 100% แต่พร้อมทำงาน "ช่วย" มนุษย์ได้เป็นอย่างดี
มองไปข้างหน้า
อัตราการพัฒนาจาก 12% เป็น 60% ในสองปี บอกให้รู้ว่า AI ที่ใช้คอมพิวเตอร์ได้เทียบเท่ามนุษย์ ไม่ใช่เรื่องของ "ถ้า" แต่เป็นเรื่องของ "เมื่อไหร่"
องค์กรที่เริ่มทำความเข้าใจข้อจำกัดและศักยภาพของ AI Agent ตั้งแต่วันนี้ จะมีข้อได้เปรียบอย่างชัดเจนเมื่อเทคโนโลยีพร้อม — เพราะไม่ใช่แค่เรื่องของ Model แต่เป็นเรื่องของ Workflow, Data, และ Process ที่ต้องเตรียมพร้อมรับ Agent ที่ "ทำงานแทน" ได้จริง
แหล่งข้อมูล



